1 Introduction
Here is something I wrote a while back while working on the design of anemometers for measuring shear stresses. Part of this work required modelling and compensating for the transfer function of tubing systems. To do this in real time we used TMS320 series DSPs, and I impelemented some large FIR filters using block-floating point FFTs.
This is is a general introduction to the FFT, and also discusses the computation of power spectra and autocorrelation. This document is generated from LaTeX using LaTeXML. Some browsers do not support MathML (ie. Chrome), so the online math display uses MathJax. Conversion is not too bad, though there are some formatting problems eg. with tabbing environments. This PDF version is neater:
2 The Discrete Fourier Transform
The Fourier transform allows an arbitrary function to be represented in terms of simple sinusoids. The Fourier transform (FT) of a function is
For this integral to exist, must be absolutely integrable. That is,
However, it is possible to express the transforms of functions that are not absolutely integrable (e.g. periodic) using the delta function . With this expression of the function, if is a periodic function with period then its transform is not continuous in but consists of impulses in the frequency domain separated by .
The Discrete Fourier Transform (DFT) is the discrete-time equivalent of the Fourier transform. A function sampled over a finite period of time is defined by a time series { , , …, }. The Discrete Fourier Transform (DFT) of is
| (1) |
For clarity the constant is defined,
then, the sum becomes:
The comparable inverse function is the Inverse Discrete Fourier Transform (IDFT):
Note that when writing series, lower case letters indicate time-series, and upper case letters denote their transforms.
The DFT is useful whenever a sampled function must be transformed between the time- and frequency-domains. Applications of this sort include:
-
•
Computation of power spectra for sampled signals.
-
•
Frequency-domain design of digital filters.
Intensive research into signal processing algorithms during the 1960s led to the development of a class of very efficient algorithms for the DFT. These Fast Fourier-Transform (FFT) algorithms led to new applications such as:
-
•
Digital filtering (convolution).
-
•
Correlation.
In these applications, the frequency-domain is used as an intermediate stage to make time-domain calculations more efficient.
3 The Fast Fourier Transform
The Fast Fourier Transform (or FFT) is a class of efficient algorithms for computing the DFT. FFT algorithms rely on being composite (ie. non-prime) to eliminate trivial products. Where the complexity11 When an algorithm has complexity O(n), kn is an upper bound on its run-time, for some constant k. of the FFT is . The basic radix-2 algorithm published by Cooley and Tukey (1965) relies on being a power of 2 and is . Other algorithms exist which give better performance. Higher radix algorithms achieve slightly better factorisation and cut down on loop overheads. Winograd’s fourier transform algorithm is based on very efficient short convolutions (Blahut, 1985). However, the saving from using these algorithms is not more than 40%, and this is at the expense of a more complex program. In addition to saving run-time, the FFT is more accurate than straightforward calculation of the DFT since the number of arithmetic operations is less, reducing the rounding error. Stockham (1966) found that two cascaded 256-point FFTs produced half as much error as a single DFT.
In order to derive the basic FFT, assume that is non-prime and make the factorisations:
| Composite size | |
| time index | |
| frequency index |
where , , and are all integers.
Rewrite the DFT sum
Now , since and are both integers. Rearranging the remaining factors gives
| (2) |
This complex expression can be readily understood when decomposed into a series of steps.
-
1.
-
2.
-
3.
-
4.
-
5.
When each substitution is made into the previous expression, the result is identical to Equation 2. However, each step is relatively simple:
-
1.
Map the input vector into a 2-dimensional array in row-major order.
-
2.
Take the DFTs of the columns in the array.
-
3.
Scale each element of the array by a complex exponential.
-
4.
Take DFTs of all the rows in the array.
-
5.
Now map the 2-dimensional array into the output vector in column-major order.
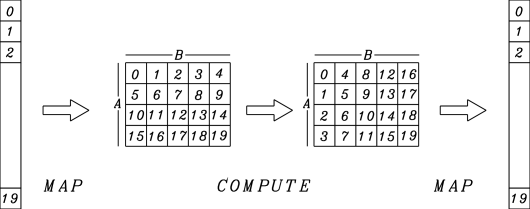
Figure 1 shows the basic structure of the process. The computation takes place on the rows, columns and elements of a 2-D array formed from the original sequence. The -point DFT has been decomposed into a series of steps.
-
1.
Mapping [ ] [ x ]
-
2.
-point DFTs (one per column)
-
3.
complex multiplications
-
4.
-point DFTs (one per row)
-
5.
Mapping [ x ] [ ]
Steps 1, 3 and 5 are all O(). In the worst case, and might be prime and so the DFTs could not be further factorised. In this case the number of complex multiplications is
and additions,
so the overall complexity is . If is composite (eg. equal to ) then the representing the contribution of the -point DFTs can be replaced by giving . Thus it is advantageous to choose to be highly composite.
The previous discussion involved factorising the DFT when is non-prime. Cooley and Tukey’s original FFT procedure involves choosing , for some integer . Putting and into equation 2 gives
| (3) | |||||
| (4) |
The first equation is for ; the second is for . Together, these are the recurrence relations for the decimation-in-time (DIT) FFT. Putting and gives instead
| (5) | |||||
| (6) |
The first equation is for ; the second is for . These are the recurrence relations for the decimation-in-frequency (DIF) FFT. These are the two canonical forms of the radix-2 FFT. The computational complexity of the two forms are identical. To illustrate how these relations are used, the structure of the DIT FFT is presented here in a graphical form.
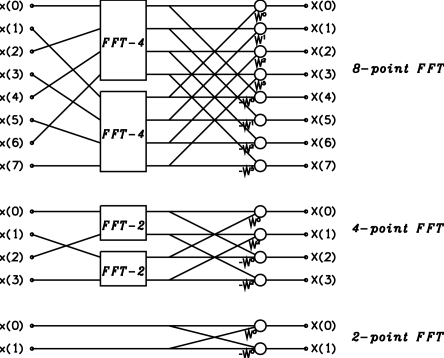
Equation 3 expresses a -point DFT in terms of two -point DFTs: the DFT of the even terms of the time-series, and the DFT of the odd terms. The equation can be applied recursively to these DFTs until , when the transform becomes trivial. Figure 2 shows these relationships graphically. A DFT is represented by a block in the diagram with inputs 0 (top) to (bottom) on the left, and outputs 0 (top) to (bottom) on the right. An open circle denotes a complex addition. A labelled line denotes a complex multiplication by the value of the label. The figure shows the flow-graphs for 8, 4, and 2-point DFTs.
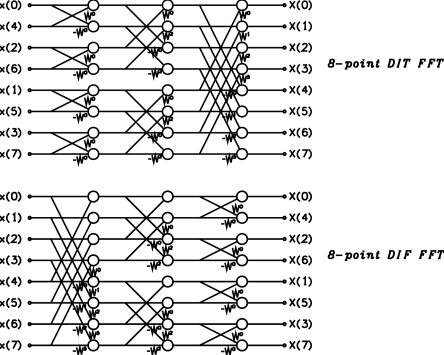
Expanding each of the DFT blocks in Figure 2 gives the graph for the 8-point DIT FFT shown in Figure 3. It also shows the flow graph for the DIF FFT, which can be derived from Equation 5 in a similar way. The major element in the graphs is a pair of parallel line connected by crossing lines. This structure is often termed a “butterfly” calculation, because of its graphical appearance. Each butterfly computation replaces its two inputs with two outputs, without affecting (or being affected by) any other butterfly at the same level in the flow graph. Thus, computation of the FFT can be done in-place with no intermediate storage required. However, the inputs to the DIT FFT (and the outputs of the DIF FFT) are not in the regular order due to the odd/even separation at each stage. In fact, the input terms are in bit-reversed order22 A number is bit-reversed for k digits by writing the k digits of its binary representation (including leading zeros) in reverse order. For example, when k=3, the number 3 (011) bit-reversed is 6 (110). When k=4, 3 (0011) bit-reversed is 12 (1100)., so scrambling (or unscrambling) of the data is an important stage in the transform. In applications where data is transformed, adjusted, and then inverse-transformed it is possible to avoid this scrambling by using the DIT form for the forward transform, and the DIF form for the inverse transform (or vice versa).
The FFT consists of stages, each consisting of butterflies. Each butterfly consists of 2 complex additions and one complex multiplication. Thus the FFT requires additions and multiplications and so is . A complex addition consists of 2 real additions. A complex multiplication consists of 4 real multiplications and two real additions. Letting be the real multiplication time, the real addition time,
| the time for a complex addition | |
| the time for a complex multiplication |
Each butterfly takes , and there are butterflies. Thus the proportionality constant for the FFT is
and the run-time is
4 Efficient DFT of a Real Series
When a series is real, its DFT is hermitian33A real function , is said to have even symmetry when and odd symmetry when . A complex function is said to have hermitian symmetry when , where denotes the complex conjugate (reflection in the imaginary axis). Note that all real functions are hermitian, but not all hermitian functions are real.. Calculating its DFT directly using the complex DFT involves computing redundant information. There are two optimisations for real series that are dependent on the properties of symmetry and the DFT. They will work with the FFT, but do not depend on it.
4.1 Simultaneous DFT of two Real Series
Suppose and are two real sequences of length . Form the complex sequence
Since the DFT is linear,
| (7) |
Since and are both real, their transforms are hermitian, ie.
From (7),
| (8) |
Thus, a length- DFT and complex additions, gives the DFT of two length- real sequences.
4.2 DFT of a Real Series using Half-Length Complex DFT
Suppose is a real sequence length . Form two length- real sequences
Now consider the transform of
and are the transforms of the real sequences and . Equation 9 gives an efficient procedure for calculating the DFT of two real sequences. Let
Then
So we have
The symmetry in this computation allows and to be computed simultaneously. Thus the DFT of a length- real sequence can be computed using a length- DFT, complex additions and complex multiplications. The run-time is therefore
For this is less than the complex FFT time
Ignoring the linear terms, the speed advantage of the real FFT over the complex FFT for large is
Thus, described technique doubles the speed of the FFT for real data. It also halves the storage requirements, since only half of the transform needs to be represented.
5 Efficient Convolution and Correlation using the FFT
Two important processes in signal analysis are
| (10) |
Suppose that the series , and are length . Each of the values of in (10) requires an integration over data points, so the processes are both . However, the convolution theorem states that in the frequency domain44 Recall that upper-case letters denote the transform of a lower-case series.
| (11) |
The computation in the frequency domain is . The cost of transforming
to and from the frequency domain using the FFT is ,
which is the most complex part of the process. The speed-up is proportional to
, so for large correlations or convolutions the advantage
of the frequency domain computation is considerable. For example, when
the order of the advantage is , ie. the
time-domain computation is roughly 100 times slower than the frequency-domain
computation.
The use of the convolution theorem is not quite as simple as
(11) suggests, since using the DFT gives a cyclic
convolution. This means that the sums and differences in the index of in
(10) are modulo . The effect of this is to make the first and
last data points contiguous, causing the convolution to “wrap around” the end
of the record. Thus, even for a short convolution the initial output is
affected by the data at the end of the record. This problem is usually solved
by appending zeroes to the original series. This cancels the contribution of
the terms that “wrap around” from the end of the series, producing an acyclic convolution.
6 Filtering using the FFT
Filtering involves acyclic convolution. The two standard sectioning techniques, which can be found in most DSP textbooks, are the “select-save” procedure (Helms, 1967) and the “overlap-add” procedure (Stockham, 1966). The “select-save” procedure uses overlapped input sections to produce non-overlapping output sections. Some of the computed output is not valid and must be discarded. The “overlap-add” procedure uses non-overlapped input sections to produce overlapping output sections that must be added together. The “overlap-add” method requires slightly more computation (since the output sections must be added) whereas the “select-save” method requires slightly more storage (to store the overlapping input). Otherwise the complexity of the two procedures is identical. The overlap-add procedure is described here.
Suppose that the input sequence has length . It is to be convolved with the sequence which represents the inverse transform of the ITF for the system (ie. the impulse response of the correction filter). Suppose has length . A length of input section is chosen such that . is the length of the transform operations, so if using a radix-2 FFT, it must be a power of 2. The length of the output section is . The last points of output must be added to the start of the next output section. The function is modified by appending zeros as follows
Define the th input section
Each input section is extended to points as follows
The product
gives the cyclic convolution of the two sequences and . However, the modifications ensure that:
-
1.
The first points of output are correct.
-
2.
The last points are contribution of the end of the current section to the start of the next section.
The points in (2) are added to the start of the output for section . The algorithm can be summarised as follows. Suppose that is the output of the convolution.
| (1) | Form and compute its transform | |
| (2) . | For = to do | |
| . | a) | Form and compute the DFT |
| . | b) . | Calculate |
| . | c) . | Compute the IDFT |
| . | d) . | Let for |
| . | e) . | Let for |
The convolution is computed with FFT operations. The computation time per sample for complex data is thus
The optimal values of and can be found by minimising this expression. According to Helms (1967) the optimal value of is approximately but departures from this value can be made without greatly increasing the running time.
7 Efficient Calculation of Autocorrelation and Power Spectra
Estimation of autocorrelation and power spectra are classical problems and are well described in the literature (Oppenheim and Schafer, 1975; Geçinki and Yavuz, 1983). They are closely related, since the power spectrum is the fourier transform of the autocorrelation. Two techniques for estimation of power spectra are:
(1) The indirect method - First, the autocorrelation of the sequence is computed. This can be done in the time-domain or in the frequency domain (using the FFT). The autocorrelation function is then transformed into the frequency domain, giving the power spectrum. To reduce leakage, the autocorrelation function is multiplied by a window before transformation.
(2) The direct method - A short section of the input is transformed into the frequency domain (using the FFT). The transformed values are each multiplied by their complex conjugate, giving an estimate of the power spectrum for that section. The process is repeated for a number of sections and the results are added to give the final power spectrum. To reduce leakage, each section of the time-domain data is multiplied by a window function before transformation. This technique is due originally to Welch (1967).
Window functions are necessary to reduce leakage in the power spectrum. The direct method appears to be more efficient, but the transform of its spectral estimator is a measure of cyclic correlation. If only the power spectrum is desired, the direct method is more efficient. However, if both the autocorrelation and the power spectrum are desired the indirect method is preferred. It also gives lower variance in the estimate (Geçinki and Yavuz, 1983).
An efficient algorithm for computing autocorrelation is given by Rader (1970). Suppose that is the input sequence of length . The inverse transform of gives the cyclic autocorrelation. To get a linear correlation, an equal number of zeros must be appended to the input sequence. However, in practice is very large compared with the number of lags desired. In this, the data can be processed in smaller sections (as described in section 6). Let denote a length sequence formed by taking points from and appending zeros as follows
Let
In the frequency domain form the product
The first elements of represent the contribution of the th section of to the autocorrelation. Let
Then the autocorrelation is given by
Rader employs the simplification
Thus, it is never necessary to form the sequence or take its transform so the required number of DFT operations is halved. Multiplying a DFT by corresponds to a shift in time of positions. Rader’s efficient algorithm can be summarised:
| (1) | Form and calculate its transform | |
| . | Let , for | |
| (2) . | For do | |
| . | a) | Form and compute |
| . | b) . | compute |
| (3) . | Let | |
| . | keeping only the first values. |
Thus the autocorrelation is computed with DFT operations (including the final IDFT). However, the number of lag values is not rigidly tied to the transform length . Lag values can be obtained by accumulating
Suppose that lag values are desired. The computation time (using the complex FFT) per sample is
where is the time per point to compute 2(b) above. can be minimised by choosing appropriately. Analytically, the minimum based on a zero derivative is
With the complex FFT, , so optimum performance obtains when . With the real FFT (for large ) so . Using the radix-2 FFT, and must be powers of 2, so if , , and
Thus, for , .